
In this notebook, we will implement RAG mechanism in addition to ReAct (Reasoning and Act) combining everything into an AI Agent from scratch. You can find the source code https://github.com/otman-ai/Implementation-of-an-AI-Agents/blob/main/Implementation_of_Research_Paper_Digest_Agent.ipynb .
What we will build ?
an AI Agent that reason and act(retrieve from the knowldge base) on the user question. We will employ RAG fusion and ReAct, RAG fusion is a type of RAG(Retrieval Augmented Generation) which is a technique in LLM to use the knowledge base including but not limited to Documents and Database.
RAG split the documents into chunks and store them in a vector database, an embedding model employed to perform search and retrieval. It has many types, one of them is RAG fusion, user ask question, RAG fusion rephrase it into sub questions and we retrieve the documents of each sub question, we rerank each document using reciprocal rank fusion. The retrieved documets are being feeded into the LLM as context.
Now for ReAct, it is prompt engineering technique introduced in 2023 at conference paper at ICLR 2023 to combine the reasoning and acting, leveraging chain of though and interacting with external enviroments.
Implementation
Installation
Before we jump into coding, we need to setup our envirement, you are welcome to use uv or conda, for this I will use pip
!pip install -qU langchain langchain-ollama langchain-chroma langchain_community pypdf
For the models, we will use ollama, so everything will be running locally, if you dont have GPUs in your machine, I recommand running this on Google Colab as it has free GPUs.
If you dont know what Ollama is software to install open source models for free. it has many models such as deepseek-r1, qwen3 and more .
For now, we are running this on Google Colab, so the installion is straightforward.
!curl -fsSL https://ollama.com/install.sh | sh
Now on the terminal run the following to start serving ollama
ollama serve
This will start the ollama server, we can use it to install and run the models. We will use nomic-embed-text for embedding the docs and llama3.1:8b for text geneation(this may take a while).
!ollama pull nomic-embed-text
!ollama pull llama3.1:8b
Now if we list the models, we should see them
!ollama list
Coding
First, we are going to import all the libraries we need.
from langchain_community.document_loaders import PyPDFLoader # loading the PDF
from langchain.text_splitter import CharacterTextSplitter # split the docs into chunks
from langchain_community.vectorstores import Chroma # for vectore store
from langchain_ollama import OllamaEmbeddings # this for running the embedding model
from langchain.prompts import ChatPromptTemplate # helps with prompting
from langchain_core.output_parsers import StrOutputParser # parser
from langchain_ollama.llms import OllamaLLM # run the LLM model
Next, we need document loader :
class DocumentLoader:
"""DocumentLoadern class"""
def __init__(self,
pdf_path:str="1810.04805v2.pdf",
chunk_size:int=300,
chunk_overlap=50) -> None:
self.pdf_path = pdf_path
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def load(self):
loader = PyPDFLoader(self.pdf_path)
pages = loader.load()
splitted_docs = CharacterTextSplitter(
chunk_size=self.chunk_size,
chunk_overlap=self.chunk_overlap,
).split_documents(pages)
return splitted_docs
There a lot going on here, we start by defining the paramters, pdf_path the path of the document, chunk_size used to define the maximum number of tokens to embed in each batch then chunk_overlap which used to define amount of consecutive chunks overlap. For load function, it load the document using PyPDFLoader() then split it into chunks using split_documents() method. Now the document is loaded, we need to store it using chromadb.
class VectorDB:
"""Vector database class"""
def __init__(self, embedding_model):
self.embedding_function = OllamaEmbeddings(model=embedding_model)
def get_retriever(self, splitted_docs):
vectorstore = Chroma.from_documents(documents=splitted_docs,
embedding=self.embedding_function)
retriever = vectorstore.as_retriever()
return retriever
The above class, define embedding_functionthe embedding model. get_retriever function returns the retriever that can be triggered with .invoke() and it will return all the docs sorted from high to low score cooresponding to the input.
Last thing we need before creating the agent is the RAG fusion.
class RAGFusion:
"""RAG fusion class"""
def __init__(self, template, top_k, retriever, llm) -> None:
self.template = template
self.top_k = top_k
self.llm = OllamaLLM(model=llm)
self.retriever = retriever
self.prompt_rag_fusion = ChatPromptTemplate.from_template(template)
self.generate_queries_chain = (
self.prompt_rag_fusion
| self.llm
| StrOutputParser()
| (lambda x: x.split("\n"))
)
self.chain_rag_fusion = self.generate_queries_chain | self.retriever.map() | self.reciprocal_rank_fusion
def reciprocal_rank_fusion(self, results: list[list], k=60):
""" Reciprocal_rank_fusion that takes multiple lists of ranked documents
and an optional parameter k used in the RRF formula """
from langchain.load import dumps, loads
# Initialize a dictionary to hold fused scores for each unique document
fused_scores = {}
# Iterate through each list of ranked documents
for docs in results:
# Iterate through each document in the list, with its rank (position in the list)
for rank, doc in enumerate(docs):
# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)
doc_str = dumps(doc)
# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the current score of the document, if any
previous_score = fused_scores[doc_str]
# Update the score of the document using the RRF formula: 1 / (rank + k)
fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked results as a list of tuples, each containing the document and its fused score
return reranked_results
def invoke(self, query):
return str(self.chain_rag_fusion.invoke({"question":query})[:self.top_k])
Dont worry if that sound confusing, we will explain it in details.
Remember what is RAG fusion? it is a technique used to retrieve the highest score docs cooresponding the a question or a prompt. the user ask question, .invoke method trigger the retrieve chain self.chain_rag_fusion to the self.chain_rag_fusiontop_k similaire results in the document that stored in the self.retriever.
RAG fusion start by rephrasing the question into sub questions, that is the role of self.generate_queries_chain, it is chain of self.prompt_rag_fusion (a prompt to generate x questions from the main question), self.llm to generate those questions, StrOutputParser() for parsing the results and lambda x: x.split("\n") to split them using '\n'. Now we have an array of questions, we pass each one to self.retriever.map() to get its similaire docs then we rerank the docs based on reciprocal_rank_fusion method. The outputs are self.top_k of docs.
Now everything is clear, let's use them.
pdf_path = "1810.04805v2.pdf"
embedding_model ="nomic-embed-text"
llm_model = "llama3.1:8b"
top_k = 2
document_loader = DocumentLoader(pdf_path)
splitted_docs = document_loader.load()
retriever = VectorDB(
embedding_model=embedding_model).get_retriever(splitted_docs=splitted_docs)
template = """You are a helpful assistant that gaenerates multiple search queries bsed on a single input query. \n
Make sure you generate only the questions, no intorduction or closing
Generate multiple search queries related to: {question} \n
Output (4 queries):"""
rag_fusion = RAGFusion(template,
top_k,
retriever,
llm_model)
Alright, now have defined our variables and load the document and store it in a vectore db, next is to create helper functions.
def post_process_response(result):
lines = result.split("\n")
tool, parameters = None, None
answer_found = False
for line in lines:
if len(line) == 0:
continue
if "[though]" in line.strip().lower():
continue
elif "[input action]" in line.strip().lower():
parameters = line.strip().split(":")[-1].strip()
print("parameters:", parameters)
elif "[action]" in line.strip().lower():
tool = line.strip().split(":")[-1].strip()
print("tool:", tool)
if not tool or not parameters:
answer_found = True
return answer_found, lines
if tool is None:
raise Exception("tool not detected by model")
if parameters is None:
raise Exception("paramters not detected by model")
else:
params_list = parameters.split(",")
return answer_found, (tool, params_list)
post_process_response process the response by getting the function name if it start with action and its argument if it start with input action, split the arguments by , and return the tool and its parameters list. In case it start with final answer: that means it found the answer, no more action needed.
Next is defining tools that the llm will have access to.
def retrieving_from_knowlege_base(question):
retrieved_docs = rag_fusion.invoke(question)
return retrieved_docs
tool_keys = {
"retrieving_from_knowlege_base": retrieving_from_knowlege_base
}
tool_desc = f"""
- retrieving_from_knowlege_base: You should call this tool in case you want to retrieve from the knowledge base or the user point it out, it takes `question` as an argument.
"""
retrieving_from_knowlege_base tool to retieve from the knowledge base (docs), tool_keys dictionary to we define the functions and its keys. Last is tool_desc, this is the description of each tool, it will be feeded to the model to understind the role and how it works. Remember AI dont perform actions but rather generate the action plans, those plans are being parsed to get the tool and its arguments so we can call it and that is what we are going to do next.
To do that, we need template prompt that instruct the llm to reason and generate actions plans that know as ReAct(see fig below).
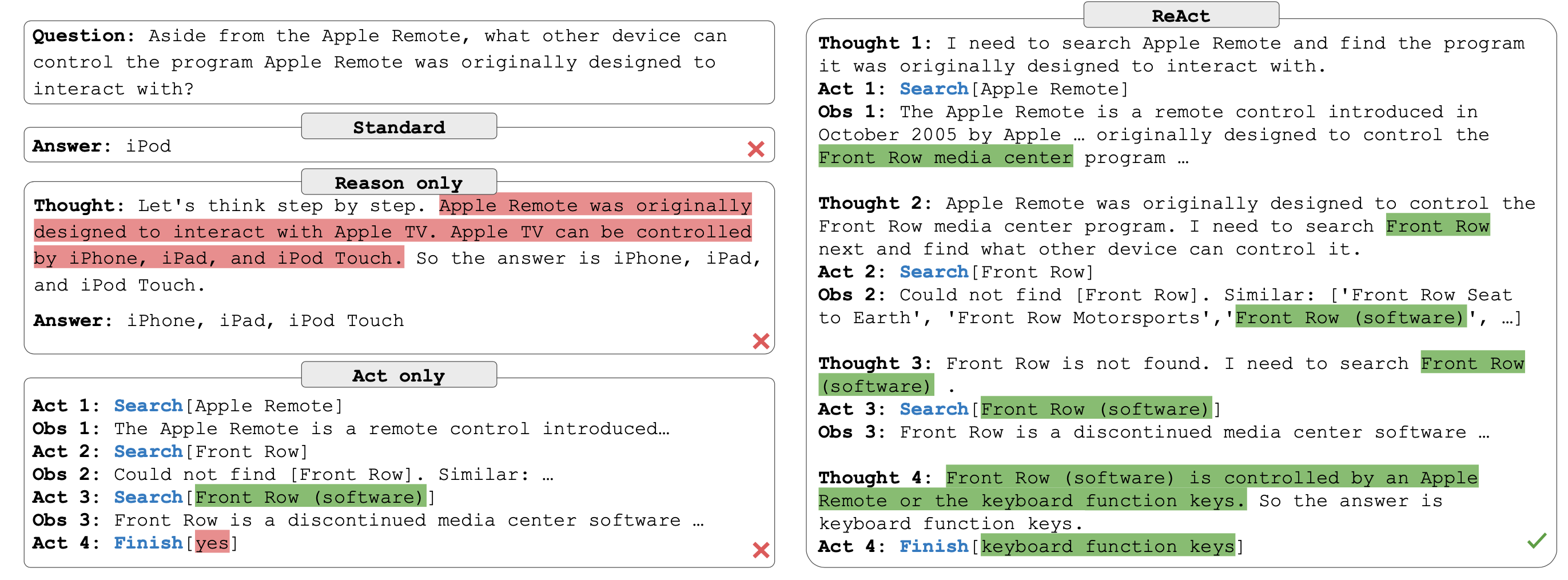
I have created one the below.
template = """
<system>
You are **Researcher Agent**, a careful and methodical AI researcher.
Your role is to analyze questions step by step, reason through evidence, and use tools to gather information when needed.
Answer the user questions as best you can.
When I say Begin that where the real converstion start.
You have access to the following tools and resources to use when needed:{tools}
You always generate an action plans with PAUSE at the end , after you got the observation then you can generate final answer.
Dont generate final answer until you have been provided with observations.
You should use the following format strictly:
Question N: the input question you must answer. Do not repeat this.
[Thought] N: think step by step about what to do including but not limited to the actions.
[Action] N: the action to take, should be one of [{tool_names}].
[Input Action] N: the arguments that will be parsed to the tool separated by a comma
Then return "PAUSE". Do not perform any action on your own.
Observation N: the result of the action
[Thought] N+1: I now know the final answer
Final Answer: the final answer to the original input question
</system>
The following are an example, Dont include it on your outputs:
<example_conversation>
user said :` Question : What is the primary function of microglia in the human brain?`
ai assistant:`
[Thought] 1: As a researcher agent, I should first clarify what microglia are and then identify their main role.
[Action] 1: retrieving_from_knowlege_base
[Input Action] 1: microglia function in human brain
PAUSE`
</example_conversation>
<example_conversation>
tool_caller: `Observation 1: Microglia are immune cells of the central nervous system responsible for protecting neurons`.
ai_assistant:`
[Thought] 2: This shows immune protection, but I need to verify if they have broader functions.
[Action] 2: retrieving_from_knowlege_base
[Input Action] 2: microglia main roles
PAUSE`
</example_conversation>
<example_conversation>
tool_caller: `Observation 2: Microglia remove debris, respond to injury, and regulate inflammation in the brain.`
ai_assistant:`
[Thought] 3: From these observations, I can conclude microglia primarily function as immune defenders and regulators in the brain.
Final Answer: Immune surveillance and protection of neurons`
</example_conversation>
<conversation_history>
{conversation_history}
</conversation_history>
BEFOR WE START, I WOULD LIKE TO MENTION AGAIN THAT FOR EVERY QUESTION YOU NEED TO REASON AND GENERATE ACTION PLAN AND END WITH `PAUSE` SO THE tool_caller can give you the observation.
Begin !
user said: `Question : {input}`
ai_assistant:`Thought {agent_scratchpad}
"""
First, we have <system> tag inside it, we define the system message, the core identity, most important how to act. We set a specific answering format to act as reasoning and acting model, we start by asking question, then the we instruct the model to think and reason following by action and Input action the PAUSE, here the model stope generating the answers, now when we use post_process_response we will detect the actions and its arguments then we call it, what the function returns that we give to the model as observation, we call it tool_caller meaning after calling the tool what we get from it. We show the model some demos in <example_conversation> tag to better understind how to respond. In order to remember our chat history, we set <conversation_history> tag to pluging the 'conversation_history' in it when invoking. We then Begin by plugging the user question then ai_assistant to complete the text in agent_scratchpad.
prompt = ChatPromptTemplate.from_template(template)
llm = OllamaLLM(model=llm_model)
conversation_history = []
Next, we create the agent_excutor
def agent_excuter(query):
agent_scratchpad = ""
chain = llm_prompt | llm
count, max_loop = 0, 10
while count<max_loop:
print(f"Thinking for {count+1} time")
res = chain.invoke({"input":query, "tools":tool_desc,
"tool_names":tool_keys.keys(),
"agent_scratchpad" : agent_scratchpad,
"conversation_history":"\n".join(conversation_history)})
print(res)
conversation_history.append(f"user said:{query}")
try:
answer_found, response = post_process_response(res)
except Exception as e:
raise Exception("Exception ", e)
if answer_found:
agent_scratchpad = f"{agent_scratchpad}{res}"
conversation_history.append(agent_scratchpad)
return response, agent_scratchpad, count
else:
print(f"[Tool calling]: calling {response[0]} with args {response[1]}")
cooresponding_tool = tool_keys[response[0]]
observation = cooresponding_tool(response[1])
print(f"[Observation]: {observation}")
agent_scratchpad = f"{agent_scratchpad}{res}\ntool_caller :`Obervation {count+1}: {observation}`\nai_assistant:`\nThought {count+1}:"
conversation_history.append(agent_scratchpad)
count+=1
The agent_excutor takes query as an argument, chain the prompt with llm, then loop through max_loop which is how many times to reason if no answer found. The chain is invoked using chain.invoke, we give it the input question, tool_names, tools_desc, agent_scratchpad and chat_history. Now all this arguments are plugged into the {} in the template to chain the complete prompt. The return res are passed to post_process_response , if answer found we return it, otherwise, we parse the tool from the response and its arguments then we trigger the function. The observation is feeded to the model again and we save every response to conversation_history, ``count` keep track how many time the model reason.
GREATE, everything is setup, lets test.
while True:
query = input("Enter your query: ")
res, agent_scratchpad, count = agent_excuter(query=query)

The provided template works while with non reasoning models but you are welcome to test and see by yourself
That is it, I hope you find this helpful and you have learnt something, you can learn more about Transformers, Tokenizer and many more here. Also I am building open source projects you can find them here including but not limited to RAG.